Teejet Flat Fan Nozzle Chart
Teejet Flat Fan Nozzle Chart - The convolution can be any function of the input, but some common ones are the max value, or the mean value. One way to keep the capacity while reducing the receptive field size is to add 1x1 conv layers instead of 3x3 (i did so within the denseblocks, there the first layer is a 3x3 conv and now. A cnn will learn to recognize patterns across space while rnn is useful for solving temporal data problems. Apart from the learning rate, what are the other hyperparameters that i should tune? So, the convolutional layers reduce the input to get only the more relevant features from the image, and then the fully connected layer classify the image using those features,. And then you do cnn part for 6th frame and. Typically for a cnn architecture, in a single filter as described by your number_of_filters parameter, there is one 2d kernel per input channel. Fully convolution networks a fully convolution network (fcn) is a neural network that only performs convolution (and subsampling or upsampling) operations. But if you have separate cnn to extract features, you can extract features for last 5 frames and then pass these features to rnn. I am training a convolutional neural network for object detection. So, the convolutional layers reduce the input to get only the more relevant features from the image, and then the fully connected layer classify the image using those features,. The paper you are citing is the paper that introduced the cascaded convolution neural network. The convolution can be any function of the input, but some common ones are the max value, or the mean value. This is best demonstrated with an a diagram: A cnn will learn to recognize patterns across space while rnn is useful for solving temporal data problems. I am training a convolutional neural network for object detection. In fact, in this paper, the authors say to realize 3ddfa, we propose to combine two. Typically for a cnn architecture, in a single filter as described by your number_of_filters parameter, there is one 2d kernel per input channel. One way to keep the capacity while reducing the receptive field size is to add 1x1 conv layers instead of 3x3 (i did so within the denseblocks, there the first layer is a 3x3 conv and now. And in what order of importance? The convolution can be any function of the input, but some common ones are the max value, or the mean value. And then you do cnn part for 6th frame and. This is best demonstrated with an a diagram: One way to keep the capacity while reducing the receptive field size is to add 1x1 conv layers instead of 3x3. I am training a convolutional neural network for object detection. And then you do cnn part for 6th frame and. And in what order of importance? One way to keep the capacity while reducing the receptive field size is to add 1x1 conv layers instead of 3x3 (i did so within the denseblocks, there the first layer is a 3x3. I am training a convolutional neural network for object detection. One way to keep the capacity while reducing the receptive field size is to add 1x1 conv layers instead of 3x3 (i did so within the denseblocks, there the first layer is a 3x3 conv and now. A cnn will learn to recognize patterns across space while rnn is useful. Apart from the learning rate, what are the other hyperparameters that i should tune? The convolution can be any function of the input, but some common ones are the max value, or the mean value. This is best demonstrated with an a diagram: And then you do cnn part for 6th frame and. Fully convolution networks a fully convolution network. So, the convolutional layers reduce the input to get only the more relevant features from the image, and then the fully connected layer classify the image using those features,. In fact, in this paper, the authors say to realize 3ddfa, we propose to combine two. The paper you are citing is the paper that introduced the cascaded convolution neural network.. The convolution can be any function of the input, but some common ones are the max value, or the mean value. And then you do cnn part for 6th frame and. I am training a convolutional neural network for object detection. In fact, in this paper, the authors say to realize 3ddfa, we propose to combine two. Apart from the. I am training a convolutional neural network for object detection. Apart from the learning rate, what are the other hyperparameters that i should tune? The convolution can be any function of the input, but some common ones are the max value, or the mean value. In fact, in this paper, the authors say to realize 3ddfa, we propose to combine. Apart from the learning rate, what are the other hyperparameters that i should tune? So, the convolutional layers reduce the input to get only the more relevant features from the image, and then the fully connected layer classify the image using those features,. I am training a convolutional neural network for object detection. Typically for a cnn architecture, in a. One way to keep the capacity while reducing the receptive field size is to add 1x1 conv layers instead of 3x3 (i did so within the denseblocks, there the first layer is a 3x3 conv and now. But if you have separate cnn to extract features, you can extract features for last 5 frames and then pass these features to. And in what order of importance? But if you have separate cnn to extract features, you can extract features for last 5 frames and then pass these features to rnn. So, the convolutional layers reduce the input to get only the more relevant features from the image, and then the fully connected layer classify the image using those features,. Typically. A cnn will learn to recognize patterns across space while rnn is useful for solving temporal data problems. In fact, in this paper, the authors say to realize 3ddfa, we propose to combine two. And then you do cnn part for 6th frame and. This is best demonstrated with an a diagram: And in what order of importance? The convolution can be any function of the input, but some common ones are the max value, or the mean value. I am training a convolutional neural network for object detection. One way to keep the capacity while reducing the receptive field size is to add 1x1 conv layers instead of 3x3 (i did so within the denseblocks, there the first layer is a 3x3 conv and now. But if you have separate cnn to extract features, you can extract features for last 5 frames and then pass these features to rnn. Apart from the learning rate, what are the other hyperparameters that i should tune? Typically for a cnn architecture, in a single filter as described by your number_of_filters parameter, there is one 2d kernel per input channel.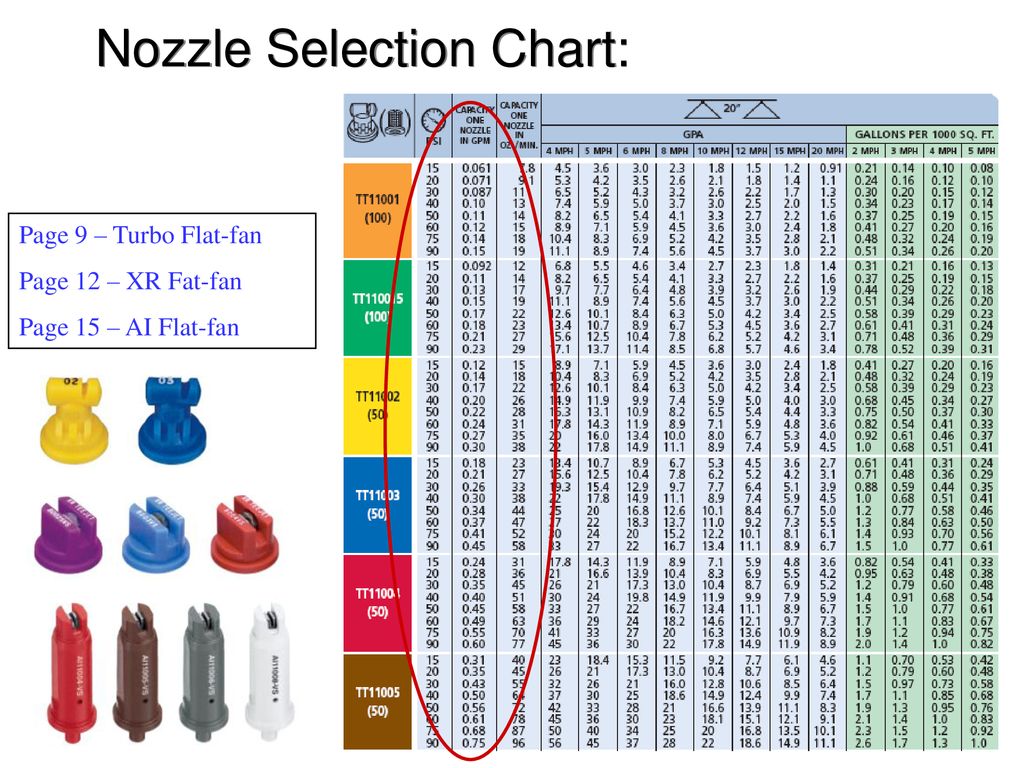
Teejet Nozzle Selection Chart Ponasa
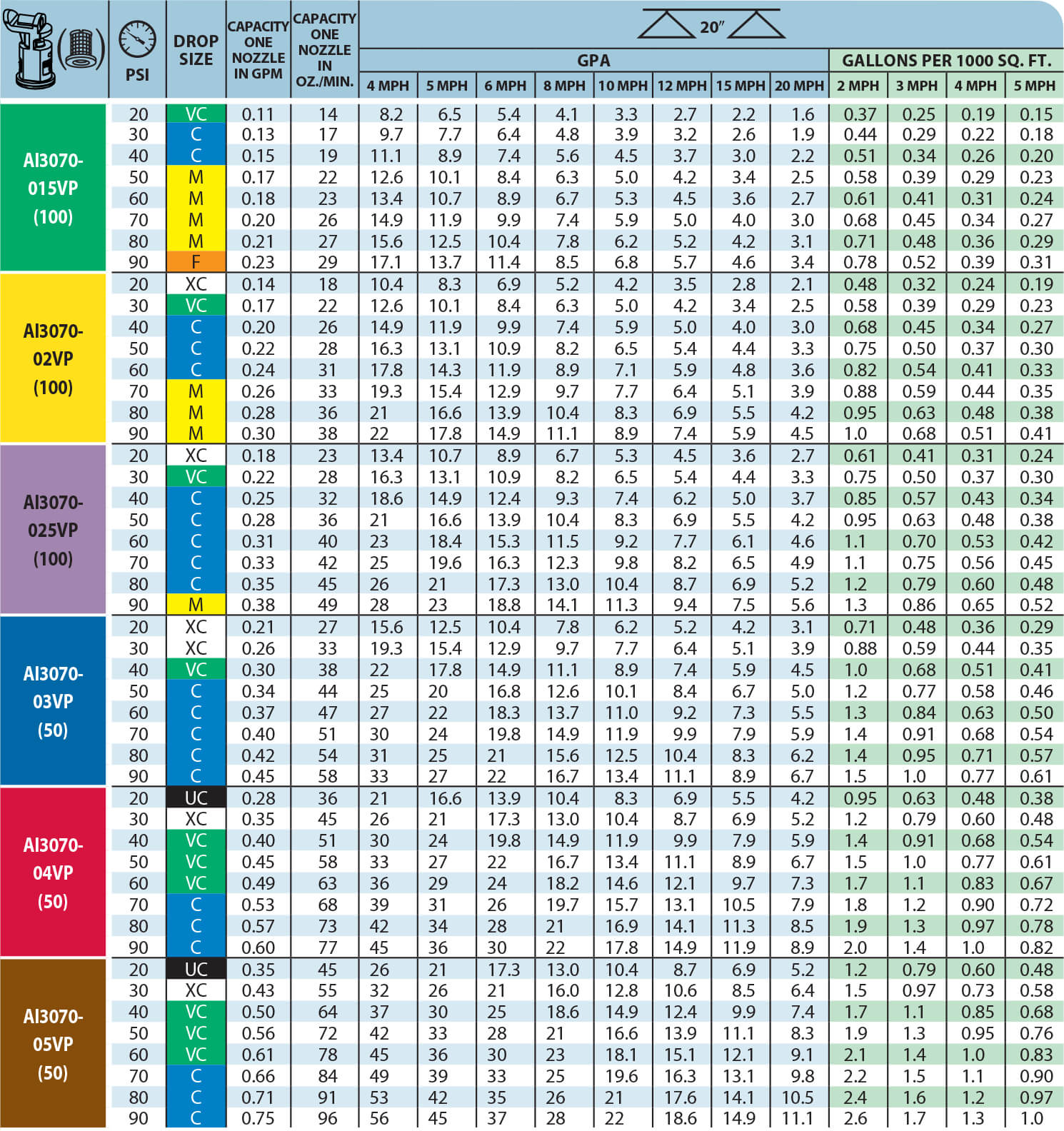
Teejet Tip Chart A Visual Reference of Charts Chart Master
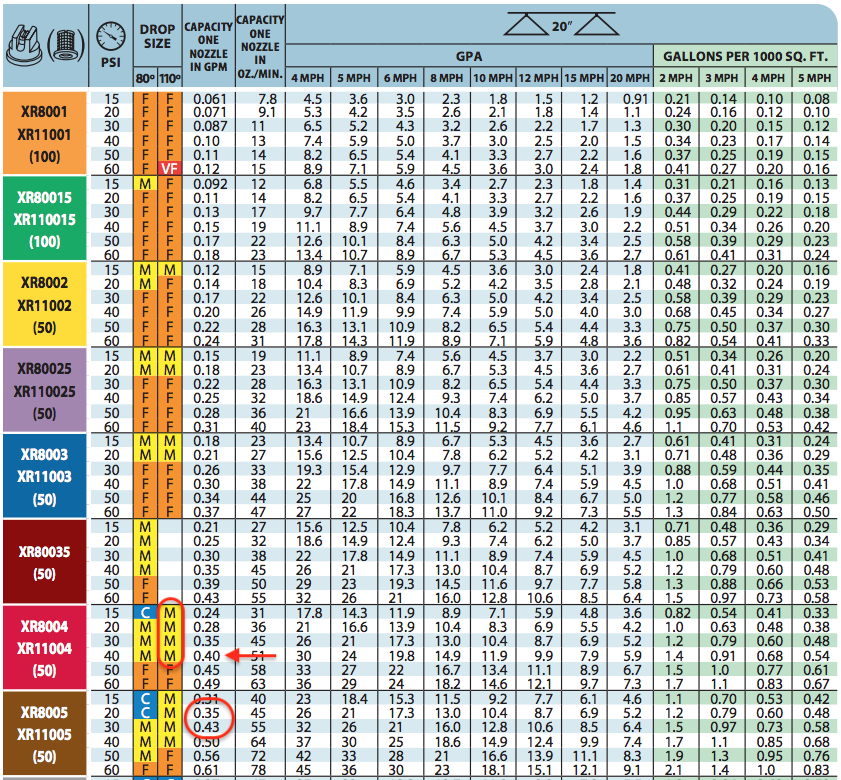
Teejet Nozzle Selection Chart Ponasa
TEEJET XR 8005VS TIP BROWN
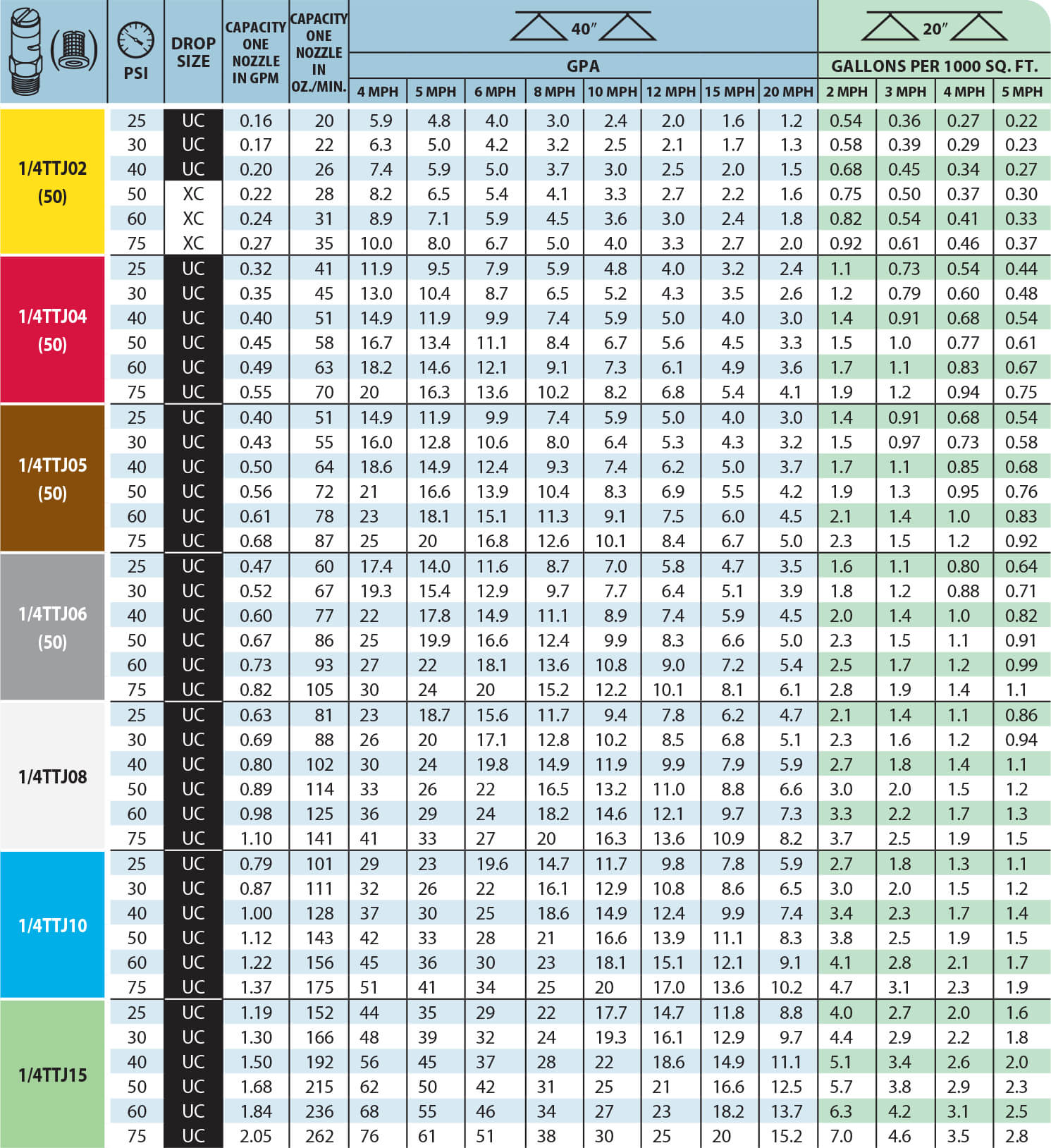
1/4TTJVP TeeJet TurfJet Wide Angle Flat Fan Spray Tip Nozzles
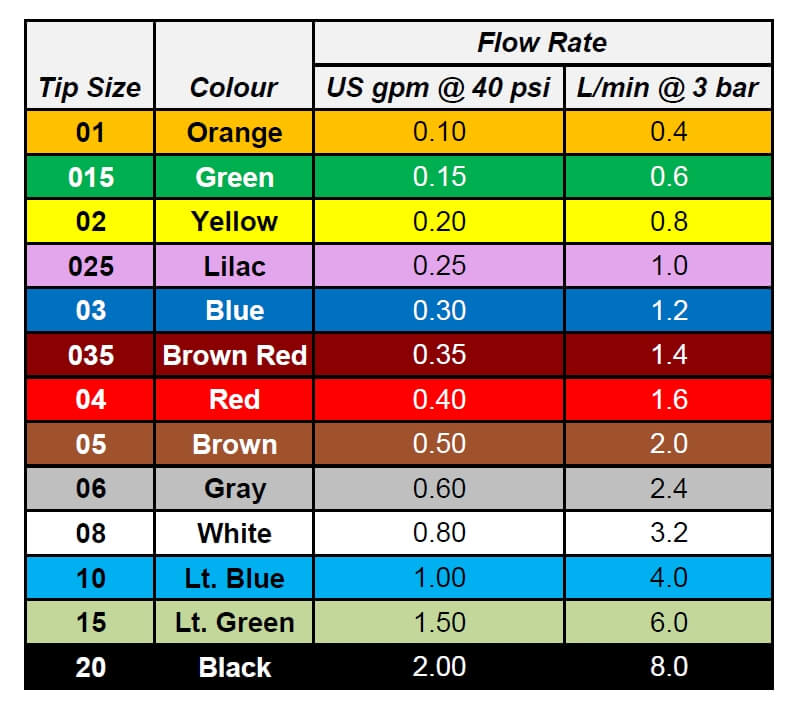
Teejet Nozzle Selection Chart Ponasa
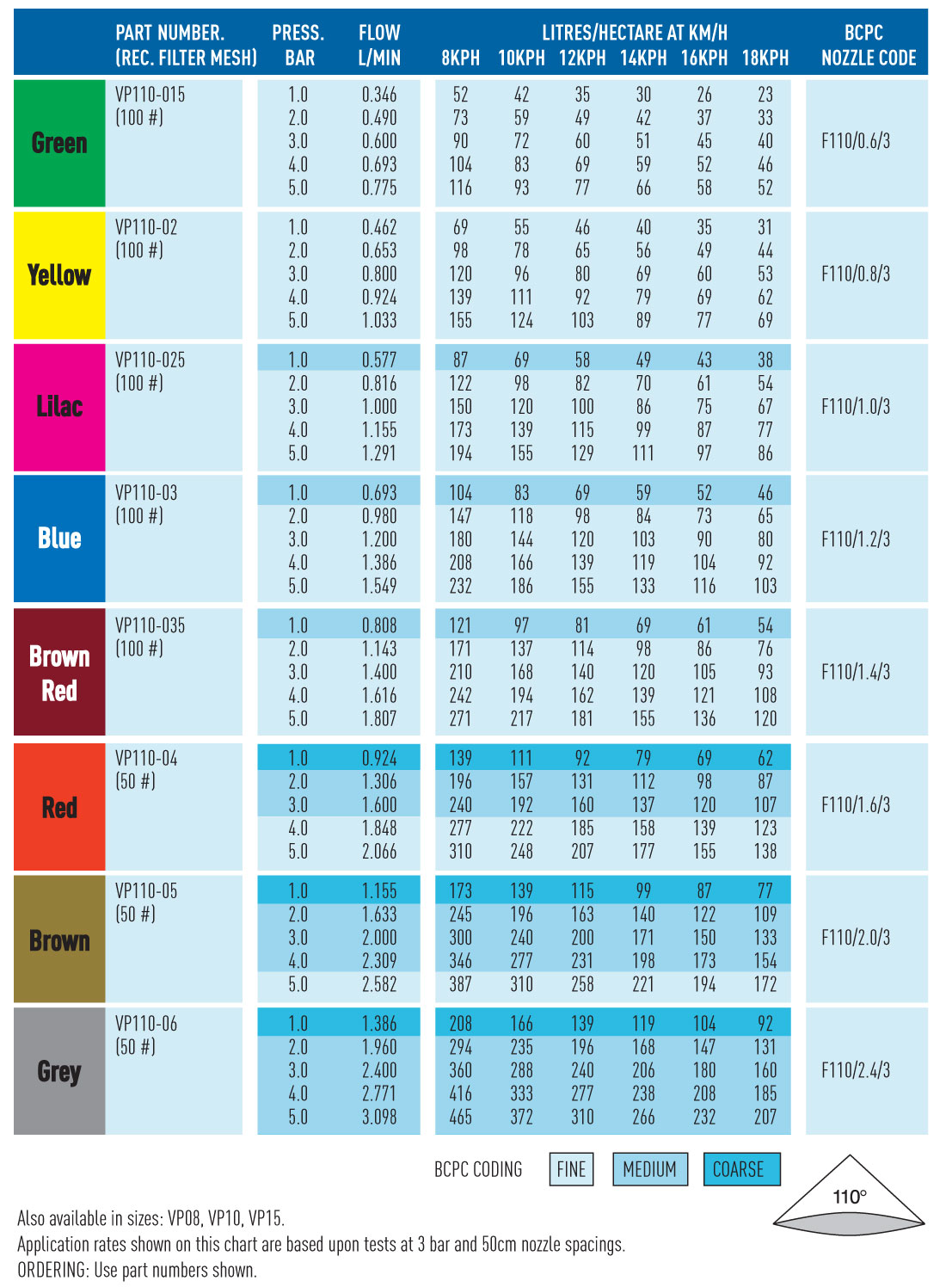
Spray Nozzle Sizing Chart at Erin Page blog
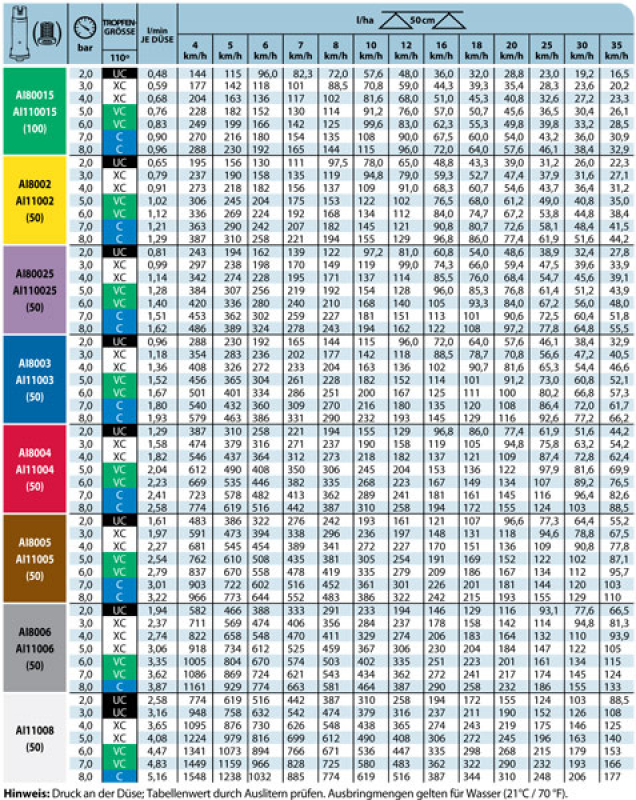
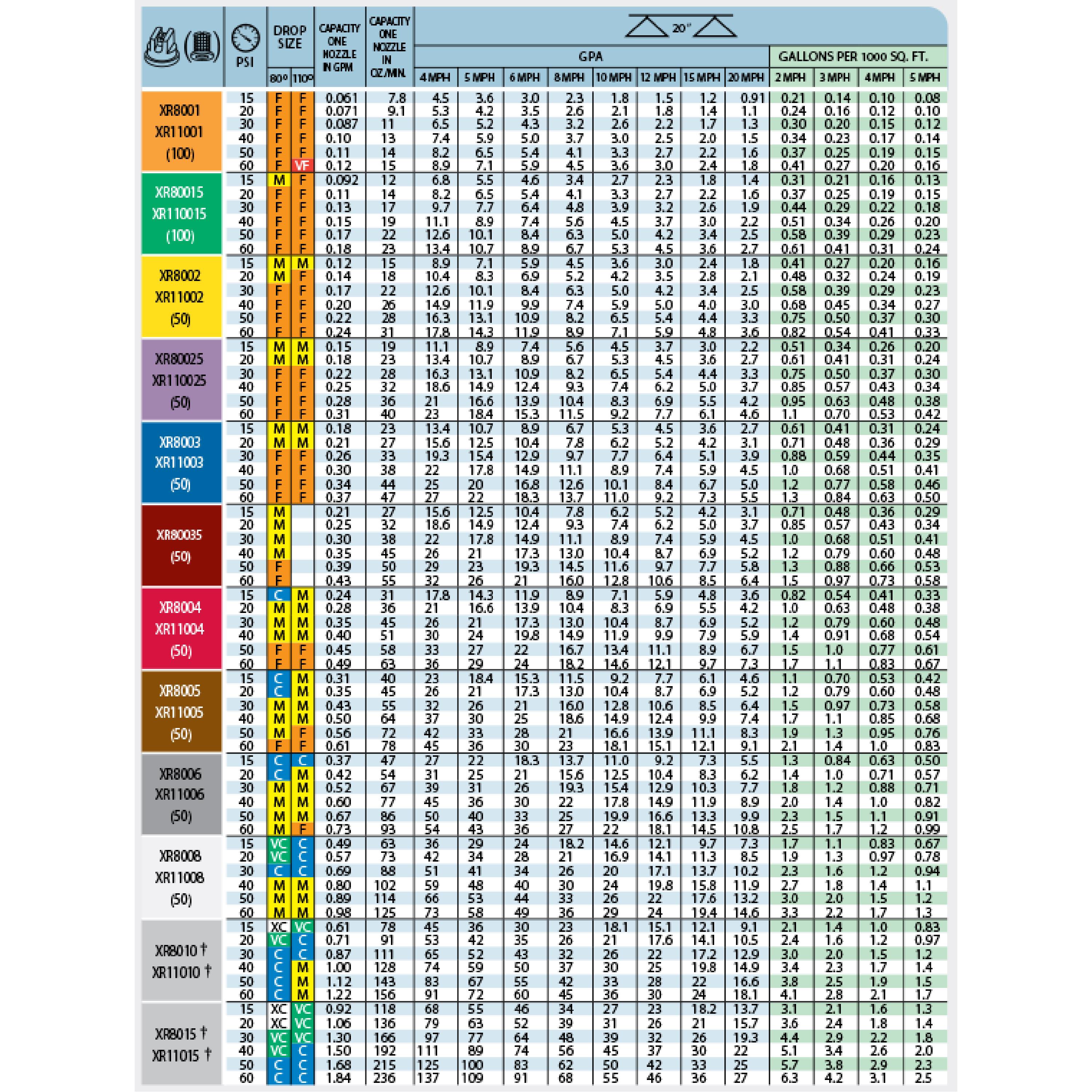
Teejet Aic Chart

Teejet Nozzle Selection Chart Ponasa
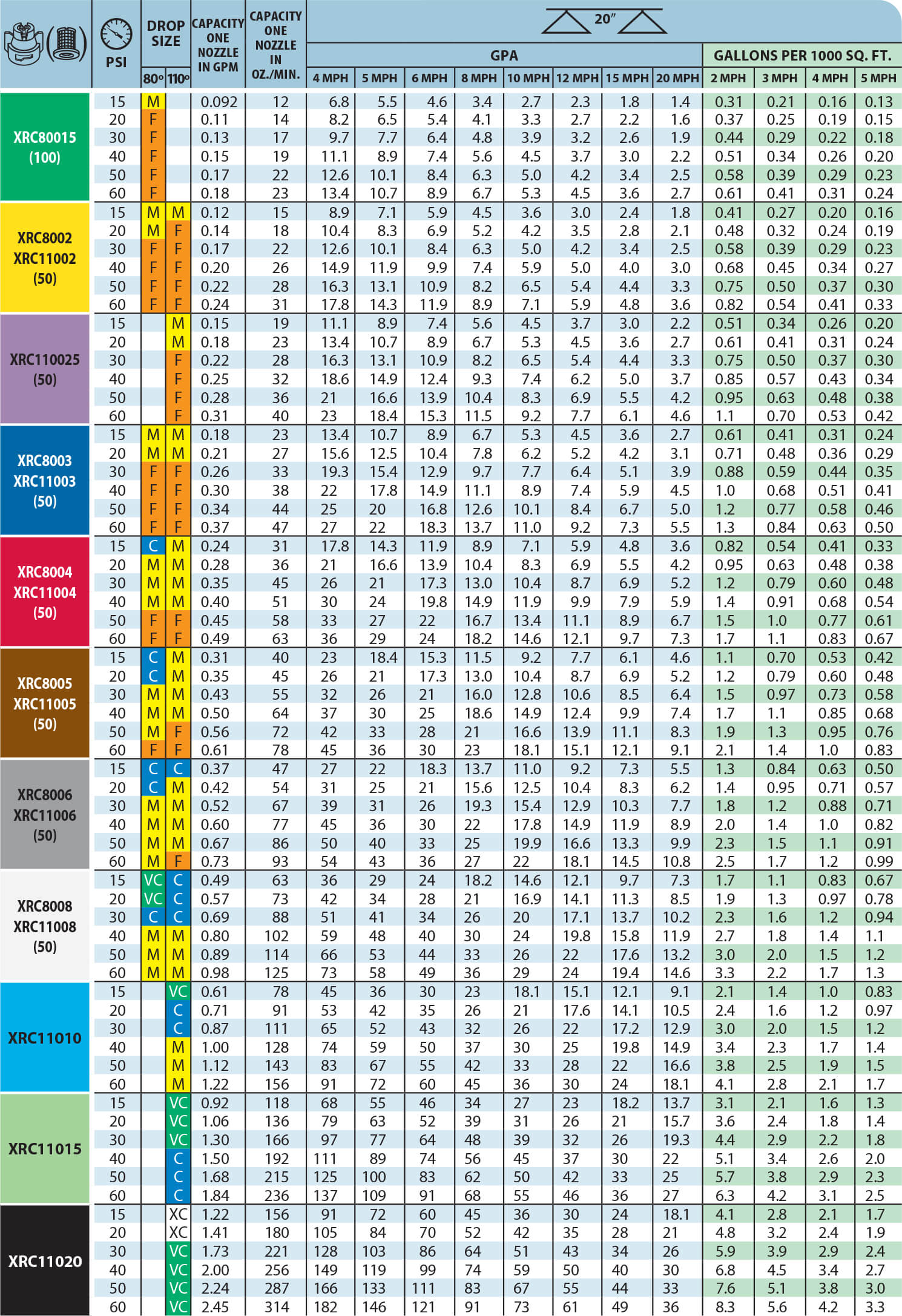
Teejet Spray Nozzle Chart A Visual Reference of Charts Chart Master
So, The Convolutional Layers Reduce The Input To Get Only The More Relevant Features From The Image, And Then The Fully Connected Layer Classify The Image Using Those Features,.
Fully Convolution Networks A Fully Convolution Network (Fcn) Is A Neural Network That Only Performs Convolution (And Subsampling Or Upsampling) Operations.
The Paper You Are Citing Is The Paper That Introduced The Cascaded Convolution Neural Network.
Related Post: